
We take security seriously, that’s why even on local intranet almost all of our services use SSL. In this article we will explain how we use SSL with other tools transparently, with little overhead. Despite our prudence, surprises occur, like this year (2020) when a simple misconception taught us a lesson.
How do we use SSL?
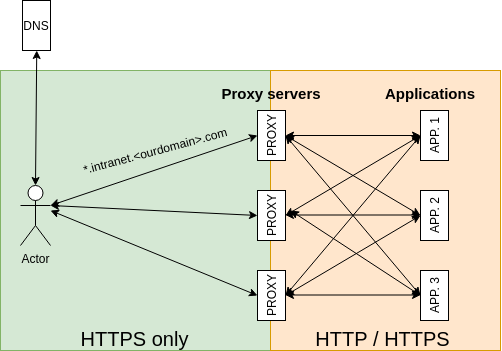
As previously mentioned, we have kept overhead to a minimum by standardizing the use of SSL. To simplify HTTP traffic, we terminate all HTTP traffic on our internal proxy servers (HAProxy). In accordance with our use of Kubernetes, all HTTP services are exposed using these proxies (multiple, to allow for load balancing and failover). SSL is terminated on these proxies, so all traffic from users to servers is encrypted. Adding new domains is simple, as we use a shared third-level domain for internal services and change only the fourth level. We have a single wildcard certificate for that third-level domain.
Certificate expiration
One certificate is shared for all internal services, therefore, we need to make sure this certificate is always valid. The certificate’s validity can lapse if it expires.
Monitoring
To be confident about our SSL infrastructure, we monitor this certificate. We have a script which checks whether a given certificate is valid and also reports its expiration date. Each year, as we approach the end of the validity period, our monitoring setup alerts us one month prior to expiration, so we have plenty of time to replace the expiring certificate with a new one. As always, the devil's in the details. We mistakenly monitored only the expiration date of our certificate and not those of certificates higher in the chain. This allowed for a higher certificate to expire and thus the whole chain became invalid. As of May 30, 2020, AddTrust Root certificate expired and unfortunately for us, that was one of the certificates in our chain.
Failing CI
So what happened next? At first not much; nobody really noticed it. Then, a few continuous integration jobs running in Docker and using the same Docker image failed when installing Python packages using pip. We thought it was just because those images were old and contained old SSL certificates, seeing as other builds using a different base image were working as expected. After a day or two, I investigated how to solve this issue without upgrading all images, as we have dozens of projects. I started by creating an environment identical to that of CI on my workstation. After a while, I figured out that OpenSSL reported that our internal Python Package index was serving an invalid SSL certificate. More on that later in this post. I thought that those old images just didn’t have up-to-date SSL root certificates. So we added read-only access to the host’s root SSL certificates from the Docker container CI is running in. This solved some issues but still not all of them.
After these changes you can imagine running the Docker container like this:
docker run --rm -it -v '/usr/share/ca-certificates/:/usr/share/ca-certificates/:ro' -v '/etc/ssl/certs/:/etc/ssl/certs/:ro' python:3.8
Internal SSL certificate
Because we still saw some SSL issues with our internal services in CI, we thought that re-issuing and getting a fresh internal certificate could resolve these issues. This is a pretty straightforward process for HTTP services as we are using HTTP proxies to terminate all SSL traffic. We downloaded new certificate and updated our proxies. All of our CI jobs started working again. The story could have ended there, but as chance would have it, it didn't.
New and bigger issue
The next morning, one of the production servers went down, from which we recovered by moving all services to a different one. After a couple of minutes the server was working again. But a lot of services started to randomly fail to validate our internal services’ SSL validity and thus marking them invalid. This was a huge issue - because we deploy Docker containers from our internal Docker Registry which was failing SSL too. So we were not able to deploy our own services because the deployment process validates SSL as well. We suspected that the SSL certificate was not updated properly, so we tried again and checked the certificate before uploading it. Then, to be sure, we restarted all HTTP proxies (a few of them had already been restarted in the morning).
After that, we started seeing self-signed certificate everywhere and no SSL was working.
After a few hours of stressful debugging we figured out that:
- Our proxy servers were validating not just the end certificate, but the whole bundle with the whole certificate chain.
- Any invalid certificate would be rejected and replaced by a self-signed certificate created by the proxy server.
- The CA bundle was invalid.
We re-created and re-uploaded the CA bundle to the proxy servers. After this the issue was finally resolved.
What exactly is a CA bundle will be explained in the second part of this article.
But why didn’t we know that those certificates were invalid in the first place, and restart the production proxies? We found out that a lot of tools and packages solve SSL verification independently and often with different results than OpenSSL.
Also, we were not prepared for this scenario, as we were monitoring the validity and expiration date of our final certificate, but not the whole chain. So this is a weak point we can definitely strengthen and improve on in the future.
Summary
In this part we've learned:
- Monitoring only the last certificate in a chain is not always enough
- even root certificates expire one day
- using an isolation mechanism (Docker for CI in our case) can introduce unnecessary complexity in handling SSL CA storage
