
At Quantlane we need to experiment a lot. When somebody has a good idea we need to try it expediently and determine whether it is profitable. This need affects our architecture greatly. We have one big trading application, of several instances, that is the heart of our system. Everything that needs to be fast and cannot be distributed is in this application. We also have a myriad of services that perform distributable, slower, and less critical functions. We use a microservice architecture because it allows us to plug in new services easily and thoroughly separate concerns of applications. However, we are not your usual company with REST microservices wherever you look. We don’t utilize the request-response pattern, but rather an event-based model. In order to react swiftly to new events, we cannot request them in a loop, because that would be very resource-demanding. We need to wait for events.
We use a messaging broker for this, specifically RabbitMQ. RabbitMQ is at the core of our microservice architecture because it takes care of getting the right messages to the right consumers. In the following sections, I would like to explain the form of messages we use and then show how we set up RabbitMQ for our needs.
Schemata
First, we need to answer a question of what messages we are going to transport, and in what form they will be delivered. We need to serialize them somehow. We could just send some JSONs and be happy... for a moment. That moment would end as soon as we needed to evolve the form of the message. We start to ask hard questions: Can all consumers handle the change? Do we have to write a similar code that handles both new and old versions in all consumers? Is there some producer that still produces the old version? How is the version identified? Right from the start, we have decided that we don't want to suffer by facing these questions. We need some sort of schema for our messages.
We've chosen Avro as our de/serialization library. It allows us to write precise schemata; we can reference other schemata and thus build hierarchies of them. We are able to use special types likes decimals or even define our own, e.g. we use NanoTime (a timestamp with nanosecond precision, represented as 'int of nanoseconds since the epoch') which is translated to the class when deserialized. This all with a smaller size footprint than JSON could have because the message contains only binary values and not field names. We define schemata in YAML format for better readability. Here's how a possible schema could look (types that starts with common are our own):
name: Trade:1
doc: A record of a transaction that took place on an exchange
namespace: messaging
type: record
fields:
- name: time
doc: Transaction time, nanosecond precision
type: common.Time:1
- name: price
doc: Price of trade
type: common.Price:1
- name: quantity
doc: Trade quantity
type: common.Quantity:1
Migrations
But wait, there's more! Our schemata have versions and migrations between them. When we decide that we want to add an ID of a trade, we can add it as another optional field:
name: Trade: 2
...
- name: id
doc: ID unique per instrument
type: ['null', string]
and add a simple migration script to it:
def forwards(v1: Dict[str, Any]) -> Dict[str, Any]:
v2 = v1.copy()
v2['id'] = None
return v2
def backwards(v2: Dict[str, Any]) -> Dict[str, Any]:
v1 = v2.copy()
del v1['id']
return v1
When we receive Trade:1, but our code understands the newer Trade:2, we add a default value of None to the field id. When it is the opposite direction we remove the redundant field. Migrations can be much more complicated - anything you can imagine in Python.
Schema Poller
We have one more feature: when we start publishing a new version of Trade, all of our consumers should know how to migrate it to the version they understand. But we don't want to first update and deploy all of our consumers, as there are usually tens of them. So we've created a schema poller, a simple code that regularly downloads new schemata from a schema repository (just a web server). So, when we release a new version of a schema along with migrations, all of our consumers have it within a minute and can continue without interruptions.
RabbitMQ
We have a solid foundation built; we know what messages we want to transport, the only question remaining is how? The how part is managed by the message broker, RabbitMQ. If you are not familiar with RabbitMQ I recommend going through the well-written RabbitMQ tutorials, which present the main concepts of the system. In the following paragraphs, I want to present our use-case of RabbitMQ. RabbitMQ lies at the core of our system and manages most of the communication between all of the services we use. The only exception is latency-sensitive data, from market exchanges to our trading platform.
Exchanges and Queues Architecture
An exchange in RabbitMQ is a connection point for publishers; when you want to publish a message in RabbitMQ, you have to decide into which exchange you are sending it. Queues, on the other hand, are a domain of consumers: a consumer reads messages that are accumulated in queues. To successfully use RabbitMQ, you have to choose the right architecture of exchanges and queues.
As our earlier article indicates, we like the publish-subscribe pattern and our messaging broker is a natural place to use it.
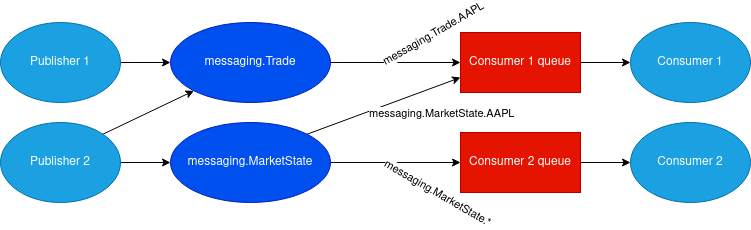
As a publisher, I want to be able to send a message into an exchange and not worry about where it will end up. To do that, we use topic exchanges that are mapped 1:1 to our schemata (mentioned earlier), e.g. when we have a schema messaging.Trade we will have also an exchange named messaging.Trade where all messages of the type will be sent.
To be able to subscribe only to what we care about, we need to set up a routing_key to each message, in our case, it is a composition of the namespace, schema name, and instrument ticker (identification of the stock), e.g. messaging.Trade.AAPL for a trade in the Apple stock. This allows our consumers to subscribe only to a certain type of message that is published for a particular stock (or all stocks if we use the wildcard, *). Each consumer then has a single queue named after it, that is bound to all exchanges (message types) via routing_key that interests them.
Settings
We use a cluster of three RabbitMQ nodes to share the load. We don't want to lose any message, so we use the strictest settings available: messages in persistent delivery mode, durable queues, publisher confirms, to name the most important settings. Here I have to recommend a great series of articles regarding the RabbitMQ best practices by CloudAMQP; if you are responsible for a RabbitMQ node or cluster you should read it. Here are some tips and tricks that helped us to set up RabbitMQ correctly:
Prefetch count is a number of unacknowledged messages that a consumer may hold. If this number is low, the consumer has to constantly ask for new messages and network latencies are slow the consumption down. If it is high, one consumer may seize all the messages available, and the other could starve with nothing to do. It is also good to limit it because otherwise, a vast number of messages could exhaust process memory.
If the publisher confirms are set, each message produced by a publisher is first stored in all queues bound to it, and only then the producer is notified that the message was successfully accepted by RabbitMQ. If the publisher code is waiting to publish the next message until publisher confirmation is returned it can substantially reduce throughput (in combination with messages persistence, it can drop to just ~120 messages per second on the same machine). To mitigate this, turn off publisher confirms or, better yet, implement a publisher confirm pool where multiple messages might be in flight.
RabbitMQ uses vm_memory_high_watermark to set the percentage of the memory available for the RabbitMQ processes. However, when run in Docker or Kubernetes, it sees the memory on the whole node, not only the memory assigned to the container. To fix this, you can add the total_memory_available_override_value option to rabbitmq.conf to tell RabbitMQ how much memory it actually has. Thus, if you want to assign 4 GiB memory to your RabbitMQ, the watermark is set to vm_memory_high_watermark.relative = 0.4 and it will run on a node with 40 GiB memory it perceives the high watermark to be 16 GiB (0.4 * 40), which is way over the limit. Set total_memory_available_override_value to 4 GiB, and everything will be as expected.
Similar to memory, Erlang checks the number of cores, and according to the count, it starts threads that schedule Erlang processes. Again, because of Docker or Kubernetes, it sees many more cores than it should and creates more scheduler threads than necessary. Scheduler threads are then constantly context switching and using a lot of CPU. This can be fixed by setting RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS to +S x:x, where x is the number of cores available to RabbitMQ. More info here.
RabbitMQ has a great tool for performance testing. It allows you to run customizable configurations on your own instance/cluster. It's best used as a Docker image.
